A Machine Learning Approach to Classifying Construction Cost Documents into the International Construction Measurement Standard
Abstract
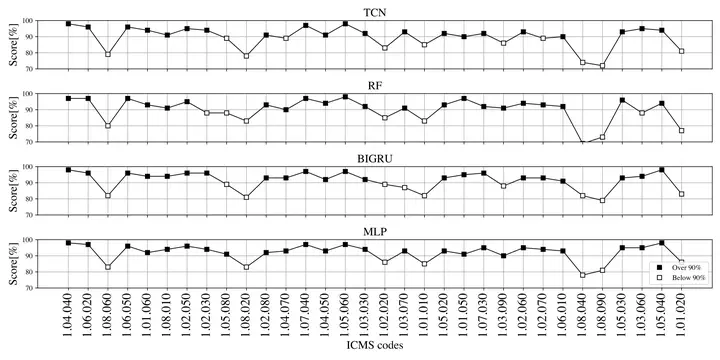
We introduce the first automated models for classifying natural language descriptions provided in cost documents called “Bills of Quantities” (BoQs) popular in the infrastructure construction industry, into the International Construction Measurement Standard (ICMS). The models we deployed and systematically evaluated for multi-class text classification are learnt from a dataset of more than 50 thousand descriptions of items retrieved from 24 large infrastructure construction projects across the United Kingdom. We describe our approach to language representation and subsequent modelling to examine the strength of contextual semantics and temporal dependency of language used in construction project documentation. To do that we evaluate two experimental pipelines to inferring ICMS codes from text, on the basis of two different language representation models and a range of state-of-the-art sequence-based classification methods, including recurrent and convolutional neural network architectures. The findings indicate a highly effective and accurate ICMS automation model is within reach, with reported accuracy results above 90% F1 score on average, on 32 ICMS categories. Furthermore, due to the specific nature of language use in the BoQs text; short, largely descriptive and technical, we find that simpler models compare favourably to achieving higher accuracy results. Our analysis suggest that information is more likely embedded in local key features in the descriptive text, which explains why a simpler generic temporal convolutional network (TCN) exhibits comparable memory to recurrent architectures with the same capacity, and subsequently outperforms these at this task.
Hisham Ihshaish
Senior Lecturer in Computer Science
My research interests include applied machine learning, data science and financial technologies.